
TL;DR
Background
This case study focuses on predicting customer conversion in the online retail space using real-world customer behavior data and enhancing these predictions with the Dark Matter algorithm. Customer conversion is crucial for business success, directly impacting revenue, growth, and competitiveness, with strategies like A/B testing fostering continuous improvement and innovation.
Results
We’ve improved our ability to accurately identify rare customer conversions, leading to cost savings by avoiding unnecessary incentives for unlikely converters and gaining deeper insights into effective customer engagement strategies. This refined approach enhances resource allocation and provides a more precise understanding of customer growth and market potential.
Background
‘Customer conversion’ in marketing and business refers to the process of transforming potential customers—those showing interest in a product or service—into actual customers who make a purchase or take a desired action, such as signing up for a newsletter.
In this case study, we aim to predict customer conversion in the online retail space using real-world customer behavior data. We then enhance these predictions by incorporating the Dark Matter algorithm into our machine learning pipeline. The dataset used in this study includes various pieces of information collected from site visitors, such as the customer’s age, gender, location, engagement level, and time spent on the site (more details provided below).
Customer conversion significantly impacts business performance, directly influencing revenue, growth, and overall success. Companies can test various strategies, such as A/B testing, to identify drivers of higher conversion rates. This approach fosters a culture of continuous improvement and innovation. Businesses that excel at converting potential customers into actual buyers can accelerate growth, enhance financial health, and gain a competitive edge in the market.
Predicting customer conversion is crucial for businesses but presents several challenges due to the complexity of customer behavior and market dynamics. Companies often lack complete data on customer interactions, or the data may be scattered across different systems or departments, making it difficult to obtain a unified view of the customer journey. Moreover, predictive models frequently rely on assumptions about customer behavior that may not hold true, especially in rapidly changing markets.
These factors make creating accurate customer conversion prediction models a complex task. It requires sophisticated data analysis, advanced machine learning techniques, and a deep understanding of the business and its customers. Even with these tools in place, predictions are often probabilistic rather than certain.
Dataset
 Customer Conversion Dataset for stuffmart.com
Customer Conversion Dataset for stuffmart.comThe “Customer Conversion Prediction Dataset” is a synthetic dataset designed to simulate a scenario for predicting customer conversion. It includes various attributes related to potential leads and their interactions with a hypothetical business or website. Key attributes include demographics (age, gender, location focused on major cities in Pakistan), engagement metrics, lead source, email interactions, device type, referral sources, and social media engagement.
The dataset’s target variable, “Conversion,” is a binary indicator (0 or 1) that shows whether a lead has converted based on specific criteria related to engagement, behavior, age, and location. The dataset is structured in CSV format, making it compatible with data analysis tools, and it is intended for developing machine learning models to predict customer conversion and optimize marketing and sales strategies.
Dataset Features:
- LeadID: A unique identifier assigned to each lead or potential customer.
- Age: The age of the lead, represented in years.
- Gender: The gender of the lead (e.g., Male, Female).
- Location: The location of the lead, with a focus on major cities in Pakistan.
- LeadSource: The source through which the lead was acquired (e.g., Social Media, Email, Organic, Referral).
- TimeSpent (minutes): The amount of time the lead spent on the website, measured in minutes.
- PagesViewed: The number of web pages viewed by the lead during their interactions.
- LeadStatus: The current status of the lead (e.g., Warm, Cold, Hot), indicating their level of interest.
- EmailSent: The number of emails sent to the lead as part of communication efforts.
- DeviceType: The type of device used by the lead to access the website (e.g., Desktop, Mobile, Tablet).

Preprocessing
Encoding
This heatmap provides insights into which features are correlated with each other, such as the positive correlation between Age and Exited (0.29), suggesting that older customers may be more likely to churn.
The heatmap also helps detect potential issues such as multicollinearity (high correlation between independent variables), which could negatively impact model performance. However, in this dataset, no such issues are immediately apparent.
Balancing
The initial step in modeling customer conversion involves analyzing the distribution of our target classes.

Here, we see an extreme imbalance in favor of non-conversion interactions. Less than 2% of the dataset constitutes customer conversion examples. This makes sense, as users often browse the site and review content before buying an item or leaving without a purchase. The challenge with this and other anomaly detection systems is addressing this imbalance effectively.
For this study, we explored two approaches: undersampling and oversampling. Resampling in a binary classification setting involves adjusting the representation of the majority or minority class to ensure machine learning algorithms are exposed to examples from each class evenly during training. Without this step, models often become biased, over predicting the majority class.
Resampling
It’s important to note that resampling was performed after splitting the data into train and validation datasets. This was done to ensure realistic metrics when predicting on the holdout dataset.
Undersampling
Our first experiment is to undersample the majority class. This is common first-pass balancing approach as it simplifies the domain space resulting in less model training time and model complexity. The obvious downside is the loss of information from the removed samples.
To undersample the majority class (non-conversion), we can choose from simple methods to more sophisticated undersampling strategies. In this case, we use `NearMiss`, a statistically intelligent undersampling technique. `NearMiss` employs the *K Neighbors* algorithm to analyze existing data points, identifying and removing those close to the decision boundary.
Oversampling
Another approach, which proves more successful for this modeling problem, is oversampling the minority class. We have various options for oversampling techniques, ranging from simple to sophisticated. For this case study, we chose the Synthetic Minority Oversampling Technique ( SMOTE).
While some oversampling strategies simply duplicate minority samples randomly—effectively giving more weight to the minority class— SMOTE creates synthetic data points for the minority class using the same K Neighbors algorithm we saw in NearMiss. In theory, these synthetic samples should give more weight to the minority class. However, some critics argue that the algorithm might alter the feature distributions across the dataset, potentially calling into question the validity of the results.
Although this concern about feature distributions when applying SMOTE to training data remains unproven, it’s worth mentioning in our case study. In future iterations, we plan to explore other oversampling techniques and combinations of over- and undersampling to further investigate this anomaly detection-adjacent problem.
Baseline vs Ensemble
For this experiment, we establish two pipelines, each incorporating the same set of downstream classification models. The first pipeline, labeled baseline , uses the dataset’s original features and target. The second pipeline integrates Ensemble AI’s Dark Matter algorithm to generate new features before training the downstream models.
Example of the two pipelines:
Baseline modeling pipeline
→ <17 features> → model → prediction
Ensemble modeling pipeline
→ <17features> → Dark Matter → <50 features> → model → prediction
Adding Dark Matter to the Pipeline
# With three lines of code, we now have 50 new features to train and validate with darkmatter = Generator(X_train.shape[1], 1, 50, "classification") darkmatter = darkmatter.fit(X_train, y_train) X_train_emb, X_val_emb = darkmatter.generate(X_train), darkmatter.generate(X_val)
BASELINE
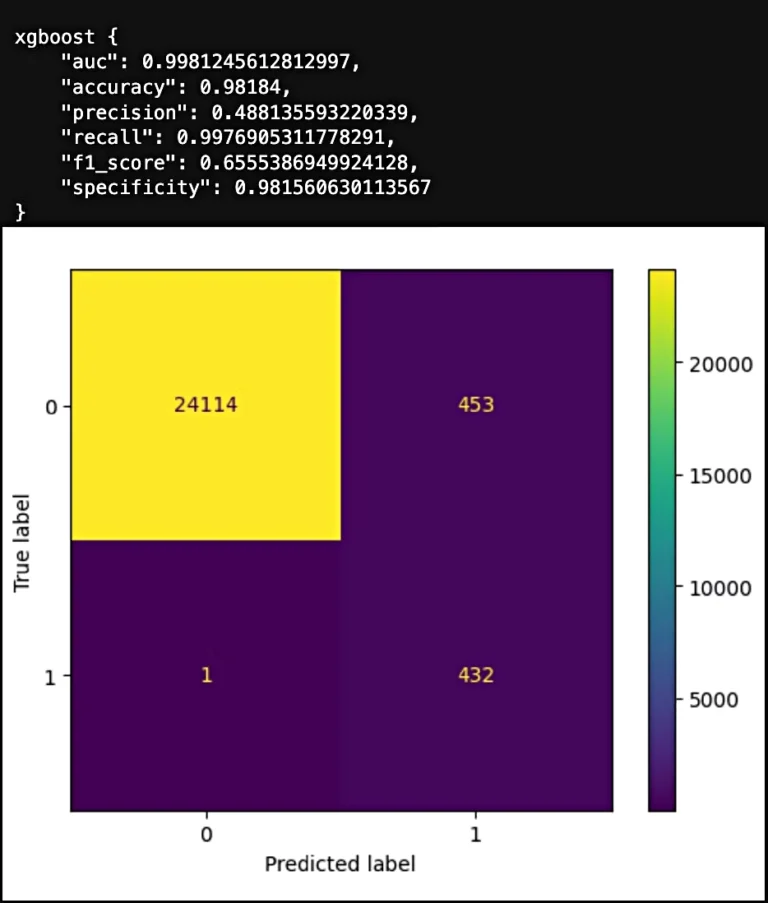
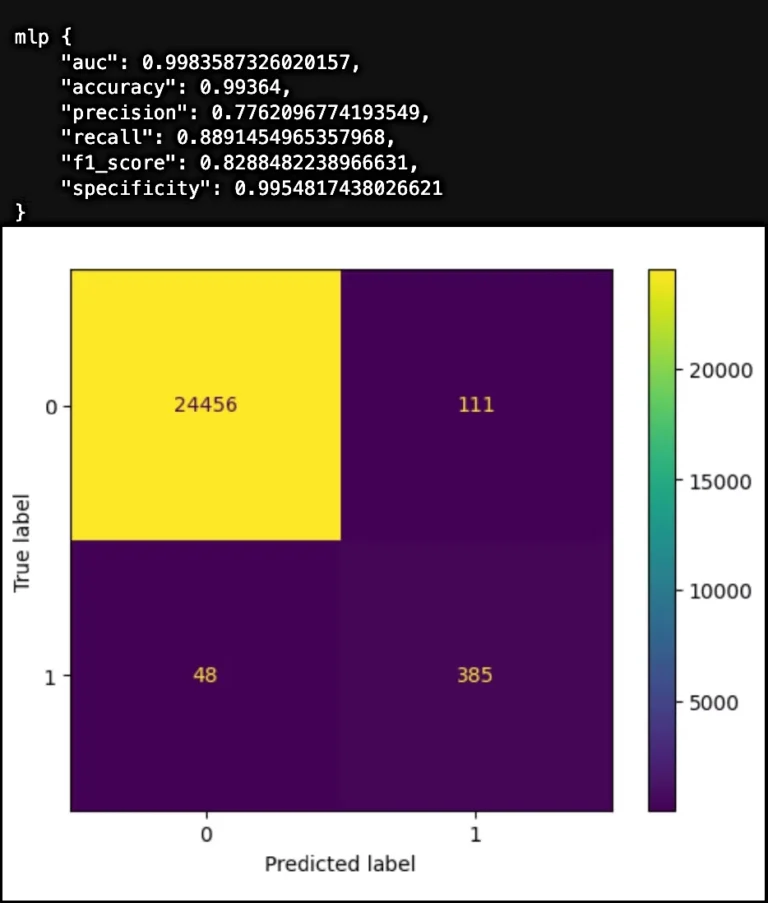
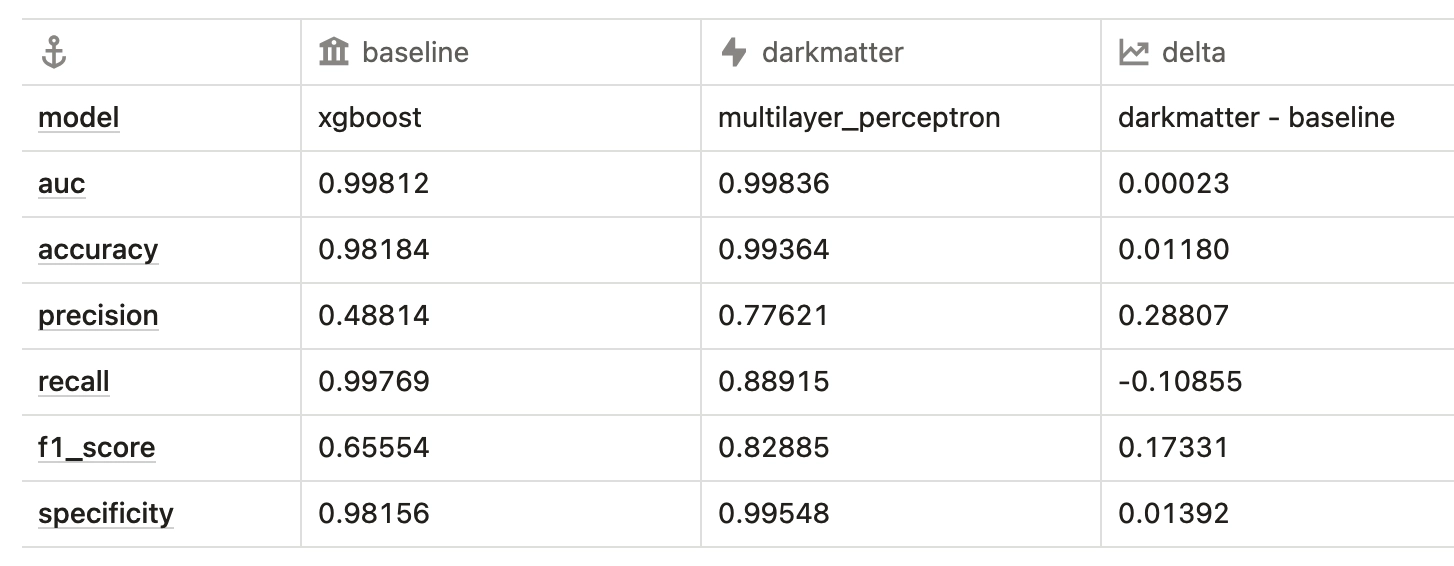
Finally, we compare each downstream model to its counterpart in the Dark Matter enhanced pipeline by examining metrics one by one. The results show improved performance across almost all models and metrics. Notably, models trained using the Dark Matter algorithm exhibit more consistent metrics, regardless of whether they’re linear or non-linear. This consistency demonstrates Dark Matter‘s effectiveness in uncovering underlying patterns within datasets, largely independent of the downstream modeling algorithm used.
Metric Comparisons
Overall accuracy improves in all downstream models across the board when using Dark Matter‘s enhanced features.
The Receiver Operating Characteristic (ROC) score, or Area Under the Curve (AUC) score, improves for most models. This metric represents the True Positive rate versus the False Positive rate, indicating enhanced prediction quality. In other words, we achieve better separability between target classes when using Dark Matter in the pipeline.
Interestingly, XGBoost and the MultiLayer Perceptron have swapped positions in their ROC/AUC scores, with the latter now outperforming the former!
Precision is clearly a challenge for this problem and dataset. Many non-conversion examples in the validation set likely closely resemble conversion examples, confusing the models. Dark Matter enhances all downstream models by replacing noise with signal. This allows them to better discern the subtle differences between customers close to conversion and those who have already converted, resulting in more accurate predictions and improved precision.
The standout here is the MultiLayer Perceptron, which has reduced its misclassification of conversions from 1 in 2 to 1 in 4!
Recall is the only metric where we see mixed results, but this makes sense. Precision and recall often trade off as we adjust the decision boundary for our predictions. Given the drastic improvements we’ve observed in precision, it’s not surprising to see this affect recall. Notably, many downstream models greatly improve their recall scores, with nearly all models converging towards a point around 0.9 recall.
The F1 score, balancing precision and recall, offers insight into our models’ overall performance and clarifies the results above. Across the board, all downstream models exhibit enhanced prediction quality. With Dark Matter, we observe improvements in both conversion identification and non-conversion recognition. This twofold enhancement suggests a more sophisticated understanding of customer behavior.
Across-the-board improvements in specificity reveal that predictions of non-conversion customers have improved in all downstream models. This means that, in addition to enhancing the models’ ability to predict conversion, using Dark Matter also improved their ability to recognize non-conversion.
Conclusion
In summary, we’ve significantly enhanced our ability to identify rare instances of customer conversion and differentiate them from the more common non-conversion behavior. This improvement has valuable business implications. We can now avoid wasting resources on futile attempts to convert unlikely visitors or unnecessarily incentivize customers who are already primed to convert.
This refined approach translates to cost savings by preventing the company from offering deals to users unlikely to change their behavior. Moreover, it provides deeper insights into the customer base and effective attraction methods, enabling more accurate analysis of customer growth and market potential.